
OneDrive Throttling Limits: Reducing Errors in Our Nightly Refresh
Accounting teams are constantly bombarded with never-ending to-do lists with impossible deadlines. FloQast’s aim is to help streamline the month-end Close process (and more!), and an important part of that process is the automated nightly refresh. We consistently refresh data from external sources like OneDrive so that when our users log into the application, their data looks accurate.

So you can imagine our panic set in when one of our largest clients, let’s call them Company ABC, reported experiencing a substantial failure rate in their nightly refreshes.

Based on our error logs, our team could pinpoint the likely cause of throttling issues thrown by their storage provider, OneDrive.

To understand how to resolve this, let’s get a better idea of how the nightly refresh works.
How the Nightly Refresh Works
Every night at midnight, a cron job kicks off and inserts messages into the overnight queue. Each message represents one company’s process to sync its records. Our workers pull these messages from the queue to work through them using the appropriate credentials of the storage provider and/or ERP (Enterprise Resource Planning). Typically, multiple messages are batched together by customer ID. For messages that are batched together, our workers work through them in series in order to avoid credential collisions.
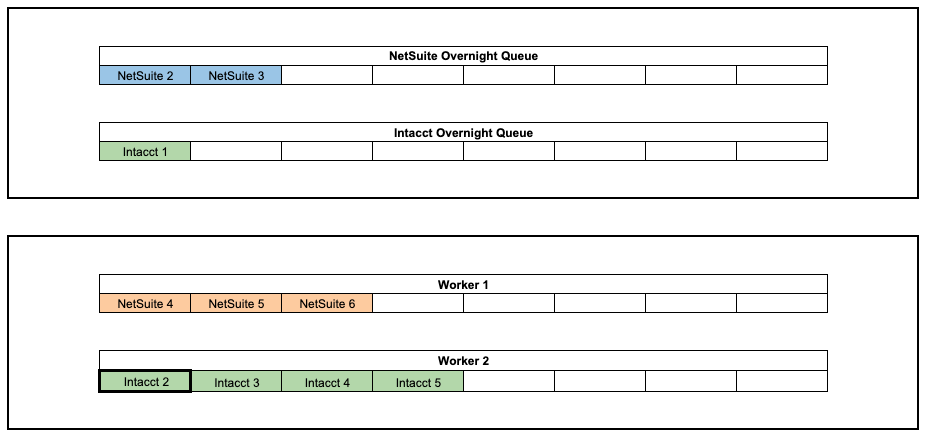
Let’s set up an example scenario:
- We have 3 Customer IDs that belong to Company ABC
- All Customer IDs share the same set of storage credentials
- 2 Customer IDs use NetSuite only (both have 3 messages each)
- 1 Customer ID uses Intacct only (has 5 messages)
- For simplicity, we have 2 overnight queues belonging to each ERP (NetSuite and Intacct) and 2 Workers that will pull messages from these queues
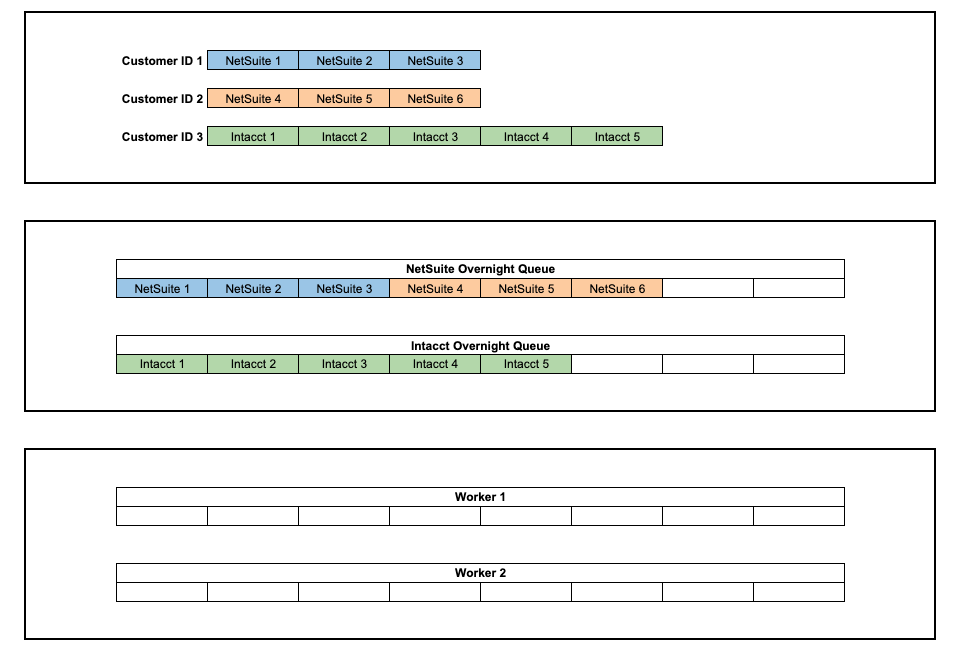
Current Behavior:
- Each Customer ID will have its messages grouped together
- The NetSuite Customer IDs are treated as different groups
- Each Worker processes the groups in series, while the groups run in parallel with each other
- Worker 1 processes the jobs for Customer IDs 1 & 2 in parallel, while Worker 2 processes Customer ID 3
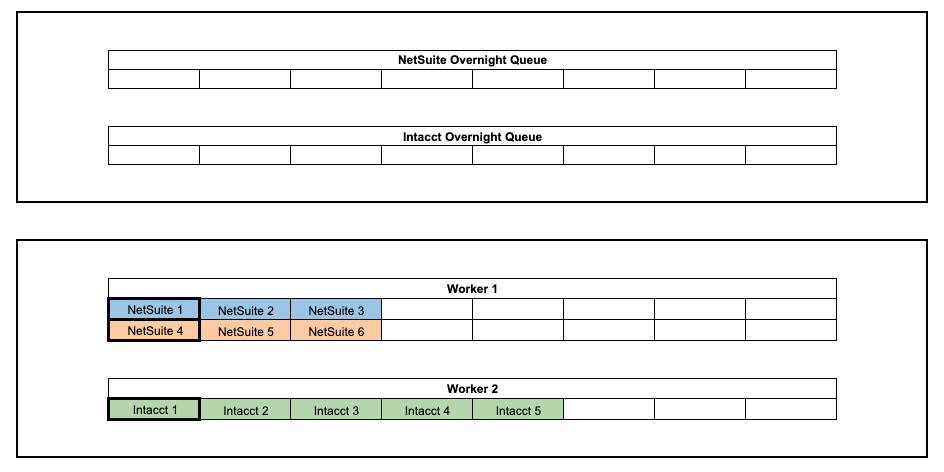
Problem #1
Due to the size of Company ABC, they have a setup of multiple customer IDs that share the same set of OneDrive credentials. The way our nightly refresh is set up spams these credentials, which causes their requests for storage data to get throttled.
The Solution, Part 1:
We explored several potential solutions and decided to group messages with OneDrive credentials differently. Instead of grouping messages based on customer ID, we grouped these messages based on a property called serviceResourceId, which represents the URL used to make API calls to get data from a given OneDrive tenant.
Continuing with our example, here is how Solution, Part 1 works:
- Both NetSuite Customer IDs will now belong to the same group
- Customer IDs 1 & 2 will not be processed concurrently and will process in series
- Workers 1 & 2 have pulled messages from different queues
- There is nothing stopping Worker 2 from using the same storage credentials as Worker 1 (Problem #2)
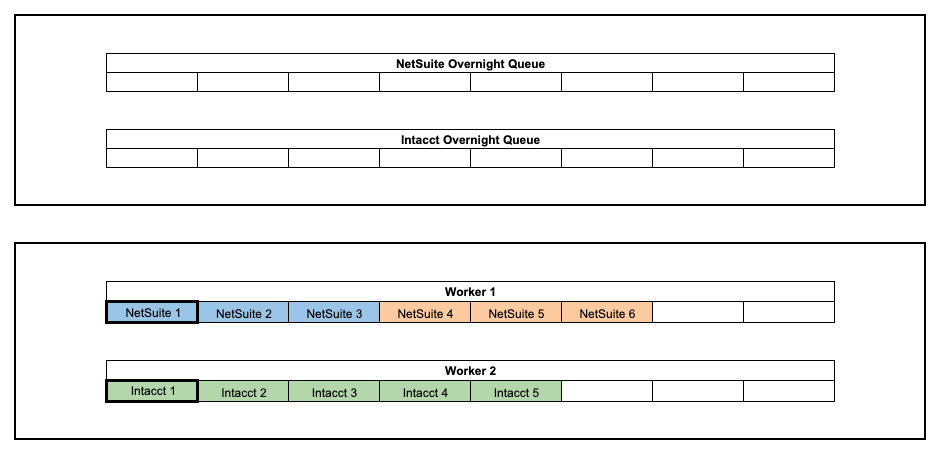
Problem #2
However, the solution above brings us to Problem #2: when messages belonging to the same group end up in different queues. We have many clients, including Company ABC, that use multiple ERPs in their accounts. Each ERP provider we support has its own corresponding queue (e.g. NetSuite messages only fall into the NetSuite queue), and the grouped mapping is only applied within a single queue, meaning a NetSuite group with group ID OneDrive1234 is not considered the same group as an Intacct group with group ID OneDrive1234 even though they technically are the same group. As a result, messages from the same group that sit in different queues will still be processed concurrently by our workers, and we run into the throttling issue again.
The Solution, Part 2:
Therefore, we added logic to re-queue messages if the credentials are in use. These messages will continuously re-queue throughout the night until the credentials are available to use.
Continuing with our example, here is how Solution, Part 2 works:
- Both NetSuite Customer IDs will still belong to the same group
- Customer IDs 1 & 2 will not be processed concurrently and will process in series
- Worker 2 finds the storage credentials are in use and re-enqueues its first message
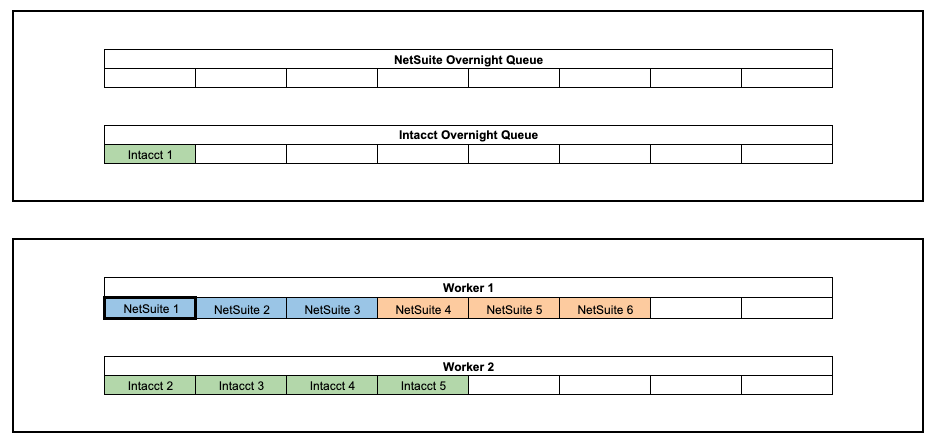
- Worker 1 and Worker 2 compete to use the credentials
- Each time a Worker finds the credentials are in use, the Worker will re-enqueue its message
- In this case, Worker 1 finishes processing 1 message
- Then Worker 2 might be able to start a message, causing Worker 1 to re-enqueue
- The Workers continue to alternate processing messages until the groups are completed
- The re-queued messages are picked up, and the process starts again until there are no remaining messages in the queue
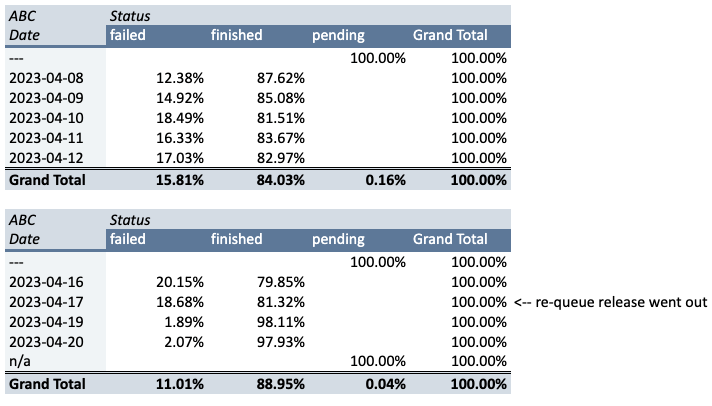
The Results
We implemented changes in a series of releases and already saw improvements in Company ABC’s nightly refresh only from using the serviceResourceId grouping – the nightly refresh success rate immediately went from 20% to 80%. The re-queue logic brought the success rate to a whopping 98%.
Obviously, this calls for a celebration!

One Last Thing
Since introducing the re-queueing logic, we saw the overnight queue would take until the mid-afternoon of the next business day to drain. We believed this timing could potentially cause issues for our users that manually trigger the refresh process for a company in the application if that particular company’s message is still in the overnight queue. Therefore, we recently released changes to expire messages that have been queueing in the overnight queue for over 8 hours so that our users are less likely to run into issues with the refresh during the business day. We knew the 98% success rate would probably decrease, but so far, no complaints or product support issues have come in, so we’ll take that as a major win.


Kristy Chu
Kristy is a Software Engineer at FloQast. She loves art, learning, and eating.
Back to Blog