
Testing for Machine Learning: QA for a Different Kind of Project
FloQast has a product called AutoRec, which helps accountants automatically reconcile transactions from two different sources. For about a year now, I’ve been the quality engineer assigned to the team responsible for the matching engine. This is the part of the AutoRec application that takes in those transactions and attempts to predict which ones reconcile, or, “match.”
Under the hood, we’re using machine learning to power the matchmaking. Most of my prior experience was with traditional web applications, so testing machine learning required a new way of thinking.

How Different Is It, Really?
Testing a machine learning project is different from testing a web application in a lot of ways, but most notably for a Quality Engineer:
- We’re not necessarily testing cases for which we know the expected outcome — We’re testing that a model can generalize given cases that it hasn’t seen before.
- That set of cases is essentially infinite.
- We’re less concerned with getting every prediction correct in the moment — We are focused on measuring accuracy and incrementally improving the model.
Needless to say…I needed a minute to reorient myself.

A Different Kind of Testing
Our team needed to reset how we approached testing this project. Traditional pass/fail tests still have their place here. However, we needed testing tools better suited to machine learning — specifically, tools built to measure and analyze.

Collecting Labels
The most essential part of our project was creating a tool to collect labels. You can think of labels as a way for us to mark which predictions are the “correct” ones. Without the labels, we wouldn’t be able to measure accuracy, train new models, or curate any data sets for running experiments. In our case, if we have the two files we’re running through the matching engine, our tool is in charge of collecting data about which rows the user intended to match.

Reporting Accuracy
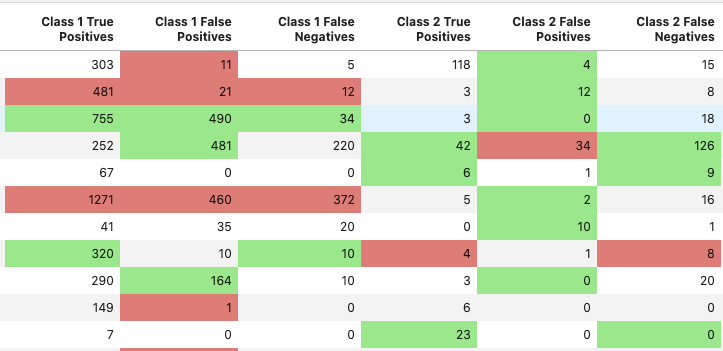
Once we have the labels, we can start to analyze how the model is doing overall. In our case, we’re using common accuracy metrics: Precision and recall. In short, precision will decrease if the model makes more false positives (predicts a match that is not labeled as a true match). Recall will decrease if the model makes more false negatives (does not predict a match that is labeled as a true match).
Our tools enable us to see these metrics at a high level and aggregate of data for a set period of time.

Or view them at a low level, for example, per job.

Additionally, we’ve built our tools so that we can easily compare the performance of two different models when running an experiment.
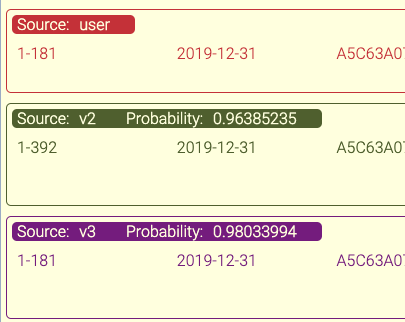
A Robust Diff Tool
Being able to diff the model results with the labels proved to be extremely valuable for us. Sometimes the stats don’t tell the whole story, so we needed a tool that gave us the differences at a transaction level. This gives us insight into what the model is doing and helps point to new ways of training.
Testing Drives Everything
The tools we built to measure and analyze model performance required the majority of our team’s focus and continue to drive most of our decision making. The team’s testing efforts are present throughout a model’s life cycle; from experiments in test environments all the way to monitoring performance in production. The data we get from our tools help us come up with new experiments to improve the model. Those experiments yield more data to pick apart and the process begins again. Our system is happily humming along in production, but the process of collecting data, analyzing it, and making iterative changes is ongoing and at the heart of what our team does.


Kristopher Clemente
Kris is a Staff Quality Engineer at Floqast and enjoys board games, video games and performing improv.
Back to Blog