
Data Transformations: Who Needs ‘em Anyways?
Like most modern-day web applications, the client-side of our app interacts with JSON data. Similarly, our development teams have historically worked mostly with JSON. Many of our third-party APIs, on the other hand, communicate using SOAP XML requests, which are structured very differently. My team’s job was to create endpoints to expose this integration data in JSON to our internal dev teams. Our goal is to keep their development as seamless as possible, minimizing their need to see data differently than they are used to.
How’s It All Look?
Of course, we first have to start by figuring out how to fetch all the third-party data and information we require. Moreover, we need to discuss and determine how this information will be passed through the request we are handling. Where do the creds go? What about the params? What will be provided in the request we receive and where? How should the response look?
These steps usually involve the most questions and necessary back-and-forths to share ideas and create clarity around an MVP. One or several members should be:
- reading API Documentation
- sending sample requests (ie. Postman)
- speaking with a tech consultant/developer from the third party to verify understanding of the API and its capabilities/limitations
Once you’ve got a successful request wired up, we can start to modify and test.

What To Return?
Now that you’ve seen the API response, next is figuring out how to parse through it, grab all the individual records and the fields wanted, or get the error code and context.


In an ideal world, all the possible statuses/shapes of the different responses/errors are known upfront and data is always complete in accordance with documentation. However, that is often not the case. Usually, it is through extensive research and trial and error, that you will gather what your team needs, what data might be unavailable, or what data requires workaround to get.
It is very important, all the while, to maintain clear communication between teams about both the product (data contract) and expectations (timing & deliverability / quality & maintenance). Ensure all the data the team expects is available. Otherwise, provide the means of aggregating that data in order to deliver a complete product.
So now the code is merged and released. Your product is in the wild, and your data is ready for consumption. It’s a great time for your team to start educating others on using your awesome new product. Some ideas include holding a working demo of the product, maybe a brown bag lunch to talk about the tech or code, and of course good ol’ handy dandy documentation.

Challenges Faced
It is one thing to be able to send a successful request and receive data in response. Understanding what that data is and how the parameters of the request are reflected in the data set, followed by repackaging that data for easier consumption by other teams (without them knowing what the original data actually looked like) are entirely different.
SO MANY WAYS TO GET THE SAME THING
In one instance testing requests for accounting balance data, we found the exclusion of certain field mappings will cause for the query under the hood to aggregate those balances, ignoring said field(s). Inclusion of departments, for example, could have no effect on the volume of data, or increase it drastically, depending on the granularity of department mappings.
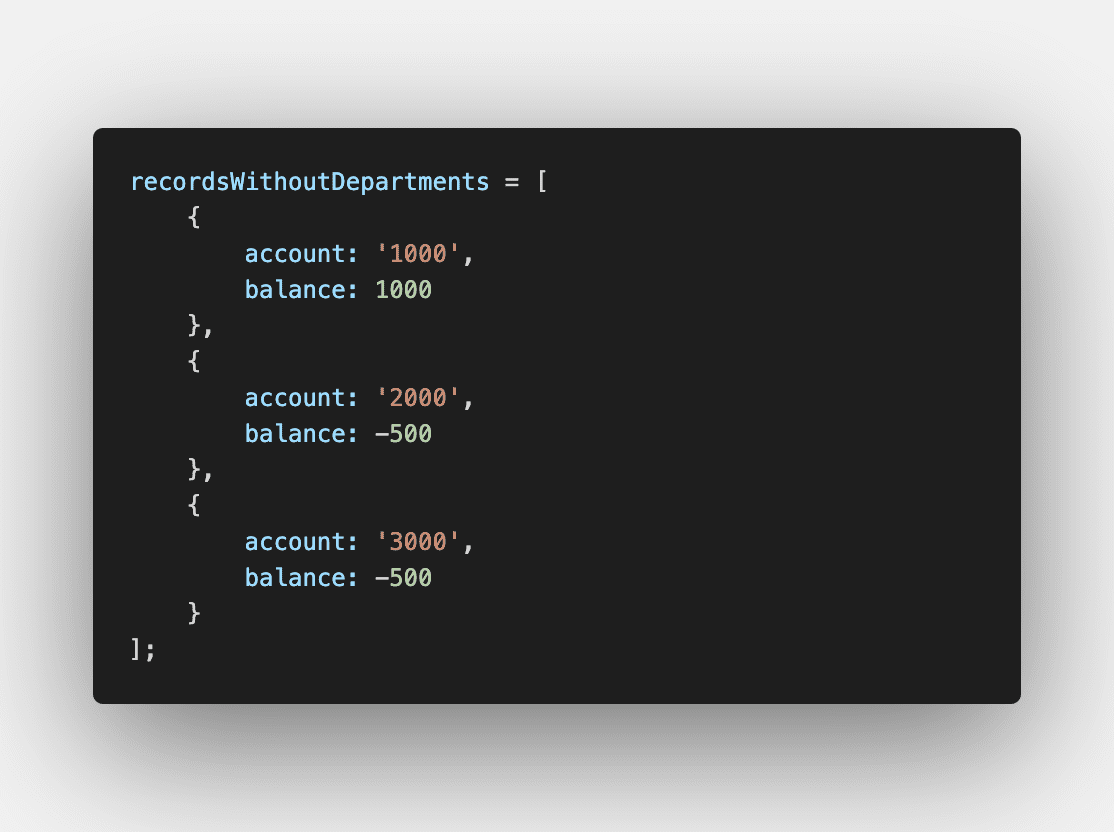
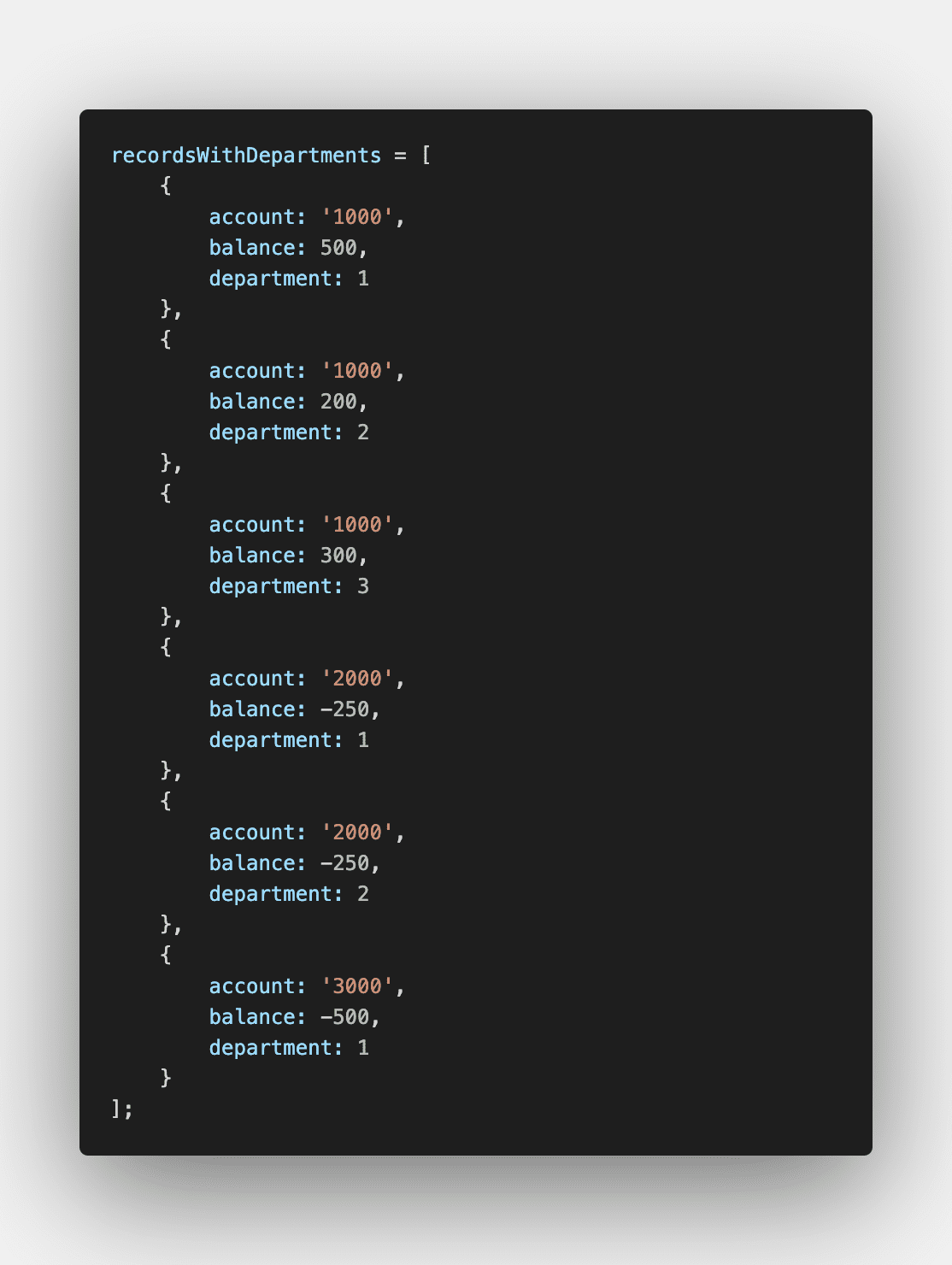
SO MANY TYPES OF THE SAME THING
Sometimes even a single record type might have variances across records and require a more nuanced parsing strategy. For example, an API can expose a single endpoint to fetch all business transactions. However, there are over 40 different types of transactions – each with their own somewhat unique schema. These transactions are all stored in the same table, and transactions of different types can be returned in any combination depending on the query. Part of our discovery here was to:
- determine all the shared and unique properties
- figure how to parse for them
- decide what to map to our JSON schema
SO MANY NAMES FOR THE SAME THING
The idea of separating the other teams from this third-party domain knowledge serves the teams by saving them time from having to learn something new. By taking raw data and reshaping it, however, you are also reshaping the conversation around the data. New references are created to fields with different naming conventions or derived fields that do not exist in the raw data. Other dev teams might always be speaking in terms of the JSON schema and its naming conventions — conventions that might deviate slightly (or completely) from the API data. Both might also deviate from the third-party UI language. The engineers responsible for the integration have to maintain the knowledge of this parity.

Tips & Notes:
Communicate, Communicate, Communicate! As expressed before, make sure to keep clear documented notes on the data contract and discovery throughout. Share knowledge and keep each other aware of statuses, progress, and roadblocks. This will help ensure that your teams are on the same right path to success.
It could help in attempting to codify data to use a typed language, like TypeScript. That way, you are always aware of the outputs and you know the data will be validated once everything is wired up. Some find typed languages to be cumbersome, but manually troubleshooting for unexpected bad data (that would have otherwise been found) can be far more painful.
Don’t forget to test!

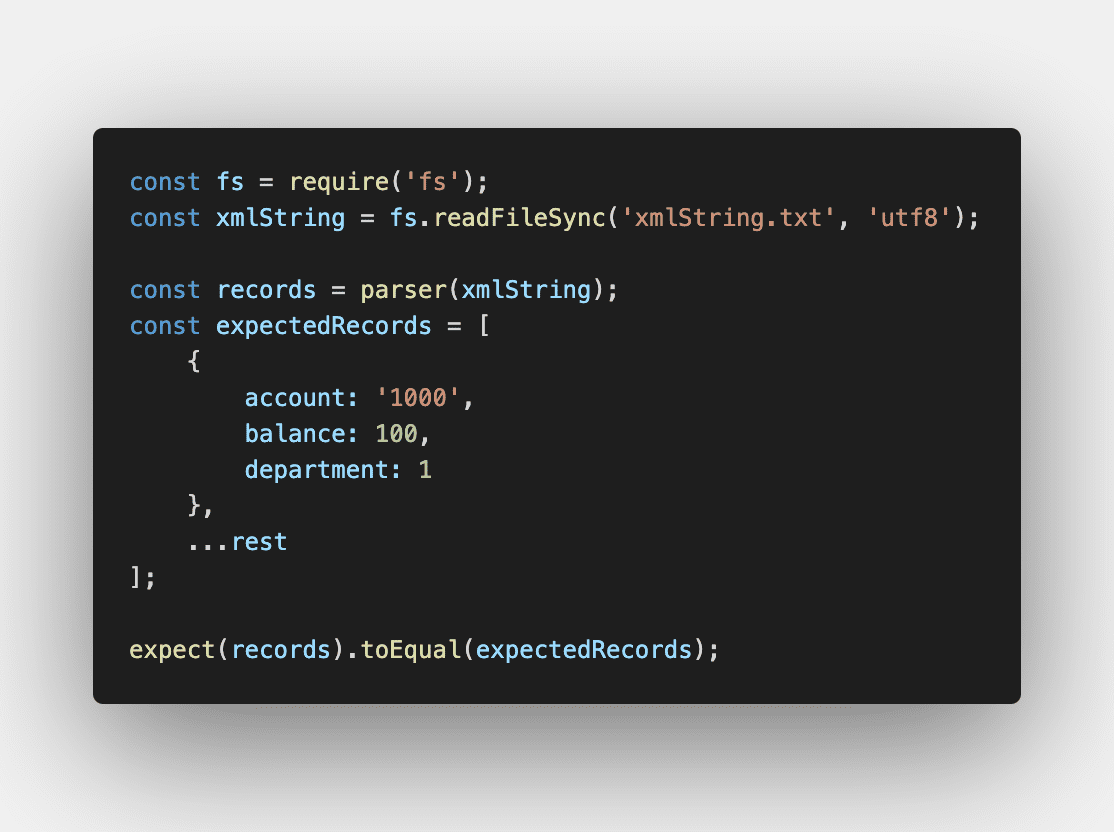
For unit testing, I highly recommend tests to ensure your request construction and response parsing strategies work as you intend. For integration tests, it may be worthwhile to invest time in setting up tests for the different edge cases of data variances to ensure the data expected for consumption is correct.
With that said, let’s get to transformin’, y’all!


Calvin Ton
Software Engineer at FloQast. Musichead and avid cratedigger.
Back to Blog