
Debug Smarter: How Logs and Traces Solve Production Issues Fast
In production environments, bugs and performance issues are inevitable. Effective debugging tools like traces and logs can save time and improve user satisfaction.
Just Another Manic Monday
You’re on a team responsible for a large software application spanning numerous client frontends, serverless functions, and internal utility libraries. This week, you’re on shield duty, which means you’re the first responder for all incoming feedback and support requests.
After grabbing your morning coffee, you open your inbox and find the following message from a very important customer—one who contributes ~30% of your product’s revenue:
Subject: The website isn’t working.
I’ve invited everyone at the company to join the app, but it’s been over an hour, and they haven’t received their verification emails. I’ve also tried uploading a file on our dashboard, but it’s not appearing. If this isn’t resolved in 24 hours, we’ll have to take our business elsewhere.
You quickly get to work, running the code locally. You invite 20 people to a team on the site, and every verification email is sent within seconds. You try uploading a file on the dashboard, and it appears as expected without any issues.
Next, you test the same scenarios in a remote development environment. Still no issues. You even try 50 different ways to break these two pieces of functionality, but everything works flawlessly.
Meanwhile, the clock is ticking, and the stakes are high. Your manager, understandably anxious about losing such a significant customer, schedules an impromptu Zoom call to check in.
You share your screen and start explaining your investigation. As you navigate between different code repositories, each one references ten more repositories to explore. The rabbit hole deepens, and soon you have dozens of VSCode tabs open, straining your computer to its limits. Your manager nervously chimes in:
“Any luck yet?”
But at this point, you just feel like you’re combing through your codebase with no end in sight.

How can we make our lives easier?
This situation can be avoided by just having a little more data. Let’s take a look at how adding traces and logs to our code can help us solve the issues presented from the fake customer request above!
Gathering the data your customers won’t send you
When debugging, it’s common to rely on the information provided by users. However, as in our example, customers often report vague issues like “the website isn’t working” and provide little to no technical details. This is where logs become invaluable—they gather critical data automatically, sparing you the need to rely on incomplete or unclear feedback.
Let’s take a look at the following code that’s handling file uploads:
const { uploadFile } = require('fake-upload-file');
const handler = ({ filename }) => {
uploadFile(filename);
};
At first glance, this snippet doesn’t give us much to work with. If fake-upload-file is an external package, we’re blind to its inner workings. Similarly, our customer hasn’t provided any information about the files they tried to upload. Without additional data, it’s hard to pinpoint the issue.
Logs help bridge this gap. Logs are just records of events that occur within your application, capturing details such as:
- What actions were performed.
- When they happened.
- Where in the code they occurred.
- Any relevant data or errors at that point in time.
By strategically placing log statements, you create a breadcrumb trail that helps you retrace the application’s steps and identify potential issues. This is especially useful when you can’t replicate the problem or when users can’t provide detailed information themselves.
There are many observability tools for collecting, storing, and analyzing logs, such as ELK Stack, Datadog, Splunk, and others. These platforms aggregate logs from various sources, providing real-time monitoring and helping you troubleshoot efficiently. For this demonstration, we’ll use Coralogix.
Let’s enhance our file upload handler with logging to capture important details:
const { uploadFile } = require('fake-upload-file');
const handler = ({ filename }) => {
try {
uploadFile(filename);
logger.info({
message: 'File uploaded successfully!',
route: 'file-upload',
filename,
});
} catch (error) {
logger.error({
message: 'Error occurred while uploading file',
route: 'file-upload',
filename,
});
throw error;
}
};
In this updated code:
- Success Logs:
- We log a success message for every file uploaded, including the
filenameandroute(set tofile-upload). - This makes it easy to filter and focus on relevant logs during troubleshooting.
- We log a success message for every file uploaded, including the
- Error Logs:
- If something goes wrong, we log an error message along with the filename and the error details (e.g.,
error.message). - This ensures critical failures are captured for future debugging.
- If something goes wrong, we log an error message along with the filename and the error details (e.g.,
By systematically adding logs to your application, you enable proactive debugging and eliminate reliance on users providing detailed reports. Now let’s use Coralogix to analyze the logs collected in production.
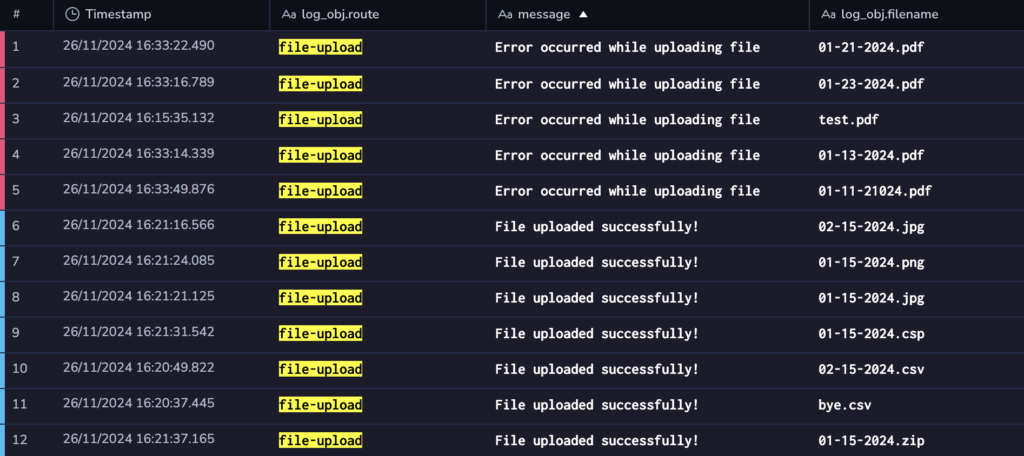
Upon inspecting the logs, you notice a pattern: all errors involve .pdf files. Let’s investigate further by examining the uploadFile function:
const uploadFile = (filename) => {
const extension = filename.split('.').pop();
if (extension === 'pdf') {
throw new Error('Not implemented yet!')
} else {
// ...logic to upload files
}
};
It turns out the utility doesn’t support .pdf files yet, and this limitation wasn’t surfaced to the customer. With this insight, you can quickly decide on next steps, such as improving error handling or updating the documentation to clarify unsupported file types.
Identifying bottlenecks in our code
Onto our next problem! The customer reported issues with verification emails not sending.
We know the customer was trying to invite a large number of employees when the issue occurred. However, let’s say this number far exceeds what we can simulate in a stress test, and local testing hasn’t shown any indication of bottlenecks.
Here’s the code that handles sending verification emails:
const getUsers = () => {
return Database.getAllUsers();
};
const filterByVerification = (users) => {
return users.reduce((filteredUsers, user) => {
if (user.requiresEmailVerification) {
return filteredUsers.concat([user]);
}
return filteredUsers;
}, []);
};
const sendVerificationEmails = (users) => {
return Promise.all(
users.map(user => EmailUtils.sendVerificationEmail(user))
);
}
const handler = async () => {
const users = await getUsers();
const usersRequiringVerification = filterByVerification(users);
await sendVerificationEmails(usersRequiringVerification);
}
What we’d really like to know is which part of the code is slowing down for the customer. Is it retrieving users from the database? Filtering users who need verification? Or perhaps sending emails in bulk?
This is where tracing comes in. Tracing is a method of tracking requests as they move through different parts of your application. Unlike logs, which provide discrete records of events, traces create a timeline of actions (called spans) that show how long each step takes. This allows you to pinpoint bottlenecks and focus on optimizing the right areas.
Let’s add tracing to this logic to track execution time for specific operations:
const getUsers = () => {
return tracing.wrap(() => {
return Database.getAllUsers();
}, 'getUsers');
};
const filterByVerification = (users) => {
return tracing.wrap(() => {
return users.reduce((filteredUsers, user) => {
if (user.requiresEmailVerification) {
return filteredUsers.concat([user]);
}
return filteredUsers;
}, []);
}, 'filterByVerification');
};
const sendVerificationEmails = (users) => {
return tracing.wrap(() => {
return Promise.all(
users.map(user => EmailUtils.sendVerificationEmail(user))
);
}, 'sendVerificationEmails');
}
const handler = async () => {
return tracing.wrap(async (span) => {
const users = await getUsers();
const usersRequiringVerification = filterByVerification(users);
span.setAttribute('numUsersRequiringVerification', usersRequiringVerification.length);
await sendVerificationEmails(usersRequiringVerification);
}, 'send-verification-emails:handler');
}
Here’s what each traced section does:
getUsers: Tracks how long it takes to retrieve all users from the database.filterByVerification: Tracks the time spent filtering users who need verification.sendVerificationEmails: Tracks the time spent sending emails in bulk.handler: Tracks the overall process and attaches metadata about the number of users requiring verification.
Once this code is deployed to production, we can view the traces in Coralogix to identify bottlenecks. Let’s look at the traces we’ve collected:
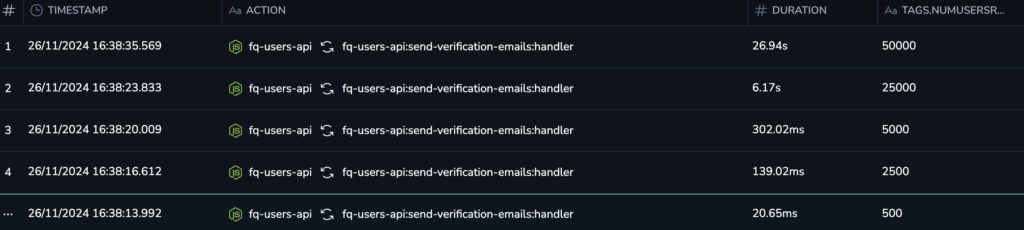
Looking at the collected traces, we can see that the send-verification-emails:handler span is taking longer as the number of users increases. Clicking on the longest-duration trace provides a detailed timeline of child spans:

Here’s the breakdown of durations for each child span:
| Span Name | Duration |
|---|---|
fq-users-api:getUsers | 80.53ms |
fq-users-api:filterByVerification | 26.32s |
fq-users-api:sendVerificationEmails | 523.92ms |
Clearly, the filterByVerification span is the bottleneck. Let’s investigate its logic:
const filterByVerification = (users) => {
return users.reduce((filteredUsers, user) => {
if (user.requiresEmailVerification) {
return filteredUsers.concat([user]);
}
return filteredUsers;
}, []);
};
The issues lies with the concat method. Each time concat is called, it creates a new array, which becomes increasingly inefficient as the size of the users array grows. This is compounded in a loop, where a new array is constructed for every iteration.
We can optimize this by using the push method instead. push modifies the array in place, eliminating the overhead of creating new arrays:
const filterByVerification = (users) => {
return users.reduce((filteredUsers, user) => {
if (user.requiresEmailVerification) {
filteredUsers.push(user);
}
return filteredUsers;
}, []);
};
Replacing concat with push eliminates this bottleneck, dramatically improving performance.
This change allows us to send verification emails faster, ensuring a better experience for our customers while maintaining system efficiency.
Somewhere in a Better Timeline…
You’re on a team responsible for a large software application, and the team understands that good traces and logs are a necessity for maintaining such a large application.
You grab your morning coffee, open your inbox, and find some feedback from a very important customer.
You ask for the customer’s ID and then open up Coralogix. Within a few minutes, you spot the bottleneck in the fq-users-api:filterByVerification logic using the traces. After identifying the issue, you swap out the inefficient concat method for the optimized push method and deploy the fix to production.
Next, you review the logs for the file-upload route. The issue becomes clear: all pdf files are failing to upload. While this problem requires a larger fix, you can quickly inform the customer that other file types should work in the meantime. This immediate feedback provides clarity and reduces frustration for the customer.
Thanks to traces and logs, you’ve not only pinpointed the issues quickly but also responded to the customer with confidence and actionable updates. The customer is impressed by your fast response and resolution. They remain a loyal partner, go on to post a glowing review of your product, and recommend your service to others in their network.

All of this success stems from the engineering team’s foresight to implement logging and tracing practices proactively. These tools turned what could have been a chaotic debugging process into a streamlined and efficient resolution.
Why Logs and Traces Are a Must-Have
As software grows in complexity, the ability to debug quickly, efficiently, and confidently becomes a competitive advantage. By adding logs and traces before issues occur, you can not only improve your ability to respond to customer concerns but also identify performance bottlenecks, system failures, and data inconsistencies faster than ever.
Investing in robust observability practices today can save you time, retain customers, and prevent headaches in the future. Logs and traces aren’t just tools for debugging—they’re tools for keeping your business and customers happy.

Tanner Lehett
Tanner is a Software Engineer II at FloQast with a passion for improving developer experience. Outside of work, he enjoys reading, board games, playing piano, and making algorithmic art.
Back to Blog