
Testen für maschinelles Lernen: QA für eine andere Art von Projekt
FloQast hat ein Produkt namens AutoRec, das Buchhaltern hilft, Transaktionen aus zwei verschiedenen Quellen automatisch abzugleichen. Seit etwa einem Jahr bin ich als Qualitätsingenieur dem Team zugewiesen, das für die Matching Engine verantwortlich ist. Dies ist der Teil der AutoRec-Anwendung, der diese Transaktionen aufnimmt und versucht, vorherzusagen, welche davon übereinstimmen.
Unter der Haube nutzen wir maschinelles Lernen, um das Matchmaking zu betreiben. Die meisten meiner früheren Erfahrungen habe ich mit traditionellen Webanwendungen gemacht, sodass das Testen von maschinellem Lernen eine neue Denkweise erforderte.

Wie anders ist es wirklich?
Das Testen eines maschinellen Lernprojekts unterscheidet sich in vielerlei Hinsicht vom Testen einer Webanwendung, vor allem aber für einen Qualitätsingenieur:
- Wir testen nicht unbedingt Fälle, für die wir das erwartete Ergebnis kennen - wir testen, ob ein Modell Fälle verallgemeinern kann, die es noch nicht gesehen hat.
- Diese Gruppe von Fällen ist im Grunde unendlich.
- Es geht uns weniger darum, jede Vorhersage sofort richtig zu machen - wir konzentrieren uns darauf, die Genauigkeit zu messen und das Modell schrittweise zu verbessern.
Unnötig zu sagen, dass ich eine Minute brauchte, um mich neu zu orientieren.

Eine andere Art der Prüfung
Unser Team musste die Art und Weise, wie wir an das Testen dieses Projekts herangehen, neu definieren. Herkömmliche Pass/Fail-Tests haben hier immer noch ihren Platz. Wir brauchten jedoch Testtools, die besser für maschinelles Lernen geeignet waren - insbesondere Tools, die zum Messen und Analysieren entwickelt wurden.

Sammeln von Etiketten
Der wichtigste Teil unseres Projekts war die Entwicklung eines Tools zum Sammeln von Etiketten. Man kann sich die Labels als eine Möglichkeit vorstellen, die "richtigen" Vorhersagen zu markieren. Ohne die Labels könnten wir die Genauigkeit nicht messen, neue Modelle trainieren oder Datensätze für Experimente zusammenstellen. In unserem Fall, wenn wir die beiden Dateien haben, die wir durch die Matching-Engine laufen lassen, ist unser Tool dafür zuständig, Daten darüber zu sammeln, welche Zeilen der Benutzer abgleichen wollte.

Genauigkeit der Berichterstattung
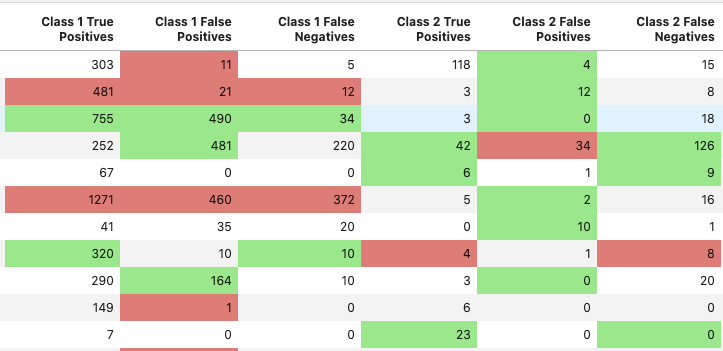
Sobald wir die Bezeichnungen haben, können wir analysieren, wie das Modell insgesamt abschneidet. In unserem Fall verwenden wir gängige Genauigkeitsmetriken: Präzision und Wiedererkennung. Kurz gesagt: Die Genauigkeit nimmt ab, wenn das Modell mehr falsch-positive Ergebnisse liefert (d. h. eine Übereinstimmung vorhersagt, die nicht als echte Übereinstimmung gekennzeichnet ist). Der Wiedererkennungswert sinkt, wenn das Modell mehr falsch-negative Ergebnisse liefert (d. h. eine Übereinstimmung vorhersagt, die nicht als echte Übereinstimmung gekennzeichnet ist).
Unsere Tools ermöglichen es uns, diese Metriken auf einer hohen Ebene zu sehen und die Daten für einen bestimmten Zeitraum zu aggregieren.

Oder Sie können sie auf einer niedrigen Ebene betrachten, zum Beispiel pro Stelle.

Außerdem haben wir unsere Tools so aufgebaut, dass wir die Leistung zweier verschiedener Modelle bei der Durchführung eines Experiments leicht vergleichen können.
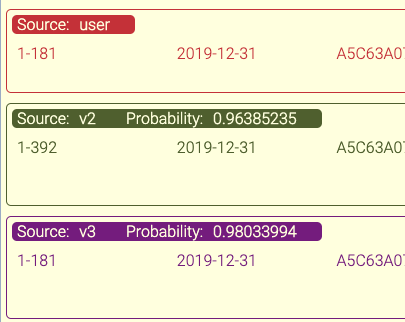
Ein robustes Diff-Tool
Die Möglichkeit, die Modellergebnisse mit den Etiketten zu vergleichen, hat sich für uns als äußerst wertvoll erwiesen. Manchmal erzählen die Statistiken nicht die ganze Geschichte, deshalb brauchten wir ein Tool, das uns die Unterschiede auf Transaktionsebene anzeigt. Dadurch erhalten wir einen Einblick in die Funktionsweise des Modells und können neue Wege für das Training aufzeigen.
Testen treibt alles an
Die Werkzeuge, die wir zur Messung und Analyse der Modellleistung entwickelt haben, nahmen den größten Teil der Arbeit unseres Teams in Anspruch und bestimmen auch weiterhin den Großteil unserer Entscheidungsfindung. Die Testarbeit des Teams erstreckt sich über den gesamten Lebenszyklus eines Modells, von Experimenten in Testumgebungen bis hin zur Überwachung der Leistung in der Produktion. Die Daten, die wir von unseren Tools erhalten, helfen uns bei der Entwicklung neuer Experimente zur Verbesserung des Modells. Diese Experimente liefern weitere Daten, die wir auswerten, und der Prozess beginnt von neuem. Unser System brummt in der Produktion vor sich hin, aber der Prozess der Datenerfassung, der Analyse und der iterativen Änderungen wird fortgesetzt und steht im Mittelpunkt der Arbeit unseres Teams.


Kristopher Clemente
Kris ist Staff Quality Engineer bei Floqast und liebt Brettspiele, Videospiele und Improvisationen.
Zurück zu Blog