
Maschinelles Lernen 101: Die Sichtweise eines Ingenieurs
Im Jahr 2019 hat FloQast ein Produkt namens AutoRec, das den Prozess der Kontenabstimmung automatisiert und Buchhaltern Stunden oder Tage spart, die sie sonst jeden Monat mit der manuellen Durchsicht von Transaktionen verbringen würden, um echte Ausnahmen oder Abstimmungsposten zu identifizieren. Dies wird häufig durch den Vergleich zweier Datensätze erreicht, z. B. des Hauptbuchs mit dem Kontoauszug.
Um diese Aufgabe zu bewältigen, haben wir eine Matching-Engine entwickelt, die mit Hilfe zahlreicher Algorithmen die Daten durchkämmt und die Transaktionen im Namen des Nutzers automatisch abgleicht. Mit der steigenden Zahl der AutoRec-Benutzer wuchs jedoch auch die Zahl der Varianten, wie die Abgleiche für die verschiedenen Kunden vorgenommen werden. Dies führte zu einer wachsenden Anzahl von Konfigurationsoptionen und einer erhöhten Komplexität der Engine sowie zu einer wachsenden Anzahl von benutzerdefinierten Konfigurationen, die für einzelne Kunden gepflegt werden mussten. Wir brauchten eine skalierbarere Lösung!
Wir fragten uns also, ob wir hier maschinelles Lernen einsetzen können. Zu diesem Zeitpunkt war ich neu im Motorenteam und hatte keine Erfahrung mit maschinellem Lernen. Ich hatte mehr Fragen als Antworten.

Auch heute noch gibt es eine Reihe von Fragen zum maschinellen Lernen (und auch eine ganze Reihe von falschen Begriffen) und seinen Möglichkeiten. Ich werde daher versuchen, Ihnen ein grundlegendes Verständnis dafür zu vermitteln, was maschinelles Lernen ist und wie es funktioniert.
Eine (sehr) kurze Einführung in maschinelles Lernen
Der Begriff "maschinelles Lernen" ist in den letzten Jahren immens populär geworden, aber es ist nicht immer klar, was genau "gelernt" wird und wie. Obwohl es sich um ein weites Feld mit vielen verschiedenen Techniken, Algorithmen und Anwendungen handelt, wollen wir das Kernkonzept des maschinellen Lernens anhand eines einfachen Beispiels erläutern.
Beginnen wir damit, wie wir Menschen aus Daten lernen können, die uns vorgelegt werden. Nehmen wir an, man gibt Ihnen die folgenden Daten und bittet Sie herauszufinden, was die Werte für A und B sein könnten:
(A x 2) + ( B x 10) = 30
(A x 3) + ( B x 20) = 55
(A x 5) + ( B x 30) = 85
Wahrscheinlich sind Sie korrekt zu dem Schluss gekommen, dass A = 5 und B = 2 ist [Anmerkung der Redaktion: Ich dachte, es gäbe keine Mathematik...]. Denken Sie nun an den Prozess, der in Ihrem Kopf stattfand, während Sie das Problem lösten. Er könnte in etwa so ausgesehen haben:
- Ermitteln Sie die Anfangswerte für A und B
- Berechnen Sie das Ergebnis für jede Zeile anhand der ausgewählten Werte
- Überprüfen Sie die Ergebnisse anhand der vorgegebenen Antworten
- Passen Sie die Werte für A und B an und wiederholen Sie den Vorgang, bis die Ergebnisse mit den Antworten übereinstimmen (so gut wie möglich).
Wir haben soeben eine Trainingsschleife! Der gleiche Prozess wird beim maschinellen Lernen verwendet, wo das Ziel darin besteht, die optimalen Werte für A und B (auch bekannt als Gewichte) auf der Grundlage der gegebenen Antworten zu lernen. Und da uns die Antworten zur Überprüfung gegeben werden, nennt man dies Überwachtes Lernen.
In diesem Beispiel haben wir zwei Eingabe Merkmaledie Werte [2, 3, 5] und [10, 20, 30], die den Gewichten A bzw. B entsprechen, aber in Wirklichkeit könnte es Hunderte oder Tausende von Features geben, die verschiedene Daten darstellen. Die Merkmale sind die Datenpunkte, die das Problem beschreiben, das man zu lösen versucht. Wenn Sie also versuchen würden, Immobilienpreise vorherzusagen, könnten Ihre Merkmale Dinge wie die Quadratmeterzahl, die Anzahl der Schlafzimmer, die Anzahl der Badezimmer usw. umfassen.
Das wirft natürlich die Frage auf:

Woher genau weiß die Maschine, wie sie den oben beschriebenen Prozess des Erratens und Einstellens der Gewichte nachahmen kann?
Wie sich herausstellt, gibt es Algorithmen, die genau wissen, wie man das macht! Das maschinelle Lernen besteht im Wesentlichen aus einer Reihe bewährter Algorithmen, die das Lernen ermöglichen. Ein solcher Algorithmus ist der Gradientenabstieg. Die Anfangsgewichte können mit Nullen oder Zufallswerten beginnen. Der interessantere Teil ist, wie er die Gewichte anpasst, um sich den richtigen Antworten zu nähern, indem er die Kosten (die Differenz zwischen den aktuellen Ergebnissen und den vorgegebenen Antworten) bei jeder Iteration minimiert. Dabei werden Formeln verwendet, die auf Ableitungen basieren, um zu bestimmen, ob die einzelnen Gewichte erhöht oder verringert werden sollten.
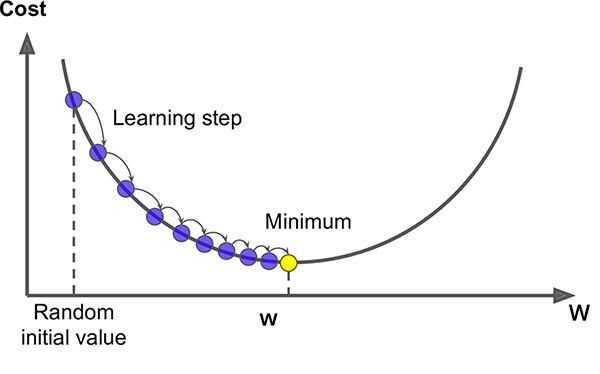
Nachdem wir nun die optimalen Gewichte auf der Grundlage der gegebenen Eingabedaten (auch bekannt als Trainingsdaten), haben wir ein Modell (Lies: Satz von Gewichtungen), das zur Vorhersage der Ausgabe für neue Daten verwendet werden kann, für die wir keine Antworten haben.
Sie können auch eine binäre Klassifizierung Problem, bei dem die Trainingsantworten entweder 1 (ja) oder 0 (nein) sind und das Modell so trainiert wird, dass es einen Wert vorhersagt (auch bekannt als eine Wahrscheinlichkeit) zwischen 0 und 1 vorherzusagen. In diesem Fall könnte man eine Wahrscheinlichkeit von 0,5 oder höher als Ja-Vorhersage betrachten.
Zurück zu unserem Transaktionsabgleichsproblem
Wenn wir einen Schritt zurücktreten und uns ansehen, was das maschinelle Lernen tut, dann lernt es die relative Bedeutung (Gewichtung) der einzelnen Merkmale in Bezug auf die vorhergesagte Ausgabe.
Für die Matching-Engine haben wir erkannt, dass wir mit Hilfe von maschinellem Lernen ein Modell trainieren können, das vorhersagen kann, ob es eine Übereinstimmung gibt, wenn wir eine Möglichkeit (d. h. Merkmale) finden, wie ein übereinstimmendes Transaktionspaar aussieht. Und es kommt noch besser: Wir müssen keine benutzerdefinierte Konfiguration verwenden, um die Variationen zwischen den FloQast-Benutzern zu berücksichtigen, da das Modell diese Variationen ganz von selbst erlernen kann, und am Ende haben wir praktisch eine Matching-Engine ohne Konfiguration, die nicht an Komplexität zunimmt, wenn mehr Kunden sie verwenden.
Auch für unsere Kunden und unser Support-Team ist es einfacher, da sie sich die Daten nicht mehr ansehen und versuchen müssen, ihre eigenen Abgleichsregeln zu erstellen, die vom Benutzer entwickelt und gepflegt werden müssen, um die besten Übereinstimmungen zu erzielen.

Ramy Georgy
Ramy ist ein leitender Software-Ingenieur bei FloQast. Er liebt Wandern, Tee und geräuchertes BBQ!
Zurück zu Blog