
Ein Anwendungsfall für eine AWS-Schrittfunktion: Serverlose ETL
Mit Batching- und Schleifentechniken nutzte FloQast AWS Step Functions als serverloses ETL-Tool, wobei die Grenzen der Datengröße eingehalten wurden.
FloQast nutzt maschinelles Lernen, um über unser AutoRec-Tool automatische Null-Konfigurationsabgleiche durchzuführen. Auch wenn der Großteil der Abgleiche automatisch erfolgt, können die Benutzer dennoch einige Anpassungen und zusätzliche Übereinstimmungen vornehmen. Wir möchten diese Anpassungen analysieren, um unseren Algorithmus zu verbessern, damit der Benutzer beim nächsten Mal weniger Anpassungen vornehmen muss. Insbesondere möchten wir einen täglichen Bericht mit wichtigen Metrikdaten (z. B. falsch positive/negative Ergebnisse) für alle Benutzer erstellen, die an einem bestimmten Tag Abgleiche durchgeführt haben.
Wir möchten, dass der Prozess serverlos abläuft, können aber aufgrund der 15-minütigen Laufzeitbeschränkung nicht eine einzige Lambda-Funktion für alles verwenden. Daher haben wir uns entschieden, den Prozess in mehrere Lambdas aufzuteilen und sie mit AWS Step Functions zu verknüpfen.
Der von uns erstellte Step Function-Workflow orchestriert Lambdas, die ihrerseits mit MongoDB-Sammlungen, DocumentDB-Sammlungen und S3-Dateien interagieren. Wie wir jedoch sehen werden, gab es Probleme mit der Datenmenge, die zu einem bestimmten Zeitpunkt durch den Workflow fließen kann. Wir haben dies gelöst, indem wir jeweils einen Datenstapel in einer Schleife durchlaufen haben. Während die Schleifenbildung mit AWS Step Functions ein bekanntes Muster ist, zeigt dieser Blog-Beitrag, wie die Schleifenbildung mit einer Paging-Technik für MongoDB kombiniert werden kann.
Unser erster Versuch
Im einfachsten Sinne muss der Arbeitsablauf eine (möglicherweise riesige) Liste von Datensätzen erfassen, einige Berechnungen an jedem dieser Datensätze mit Querverweisen auf Daten aus anderen Quellen durchführen und die Endergebnisse an einem anderen Ort speichern.
Wir beginnen den Arbeitsablauf mit dem Zeitraum, in dem wir Daten sammeln wollen, z. B:
{
"date_begin": "2020-08-18T00:00:00",
"date_end": "2020-08-20T23:59:59"
}
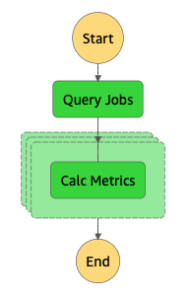
Die Schrittfunktion übergibt diese Parameter an das Lambda Query Jobs, das eine Liste aller Benutzerabstimmungsaufträge, die in den Datumsbereich fallen, aus unserer MongoDB-Sammlung "Jobs" abruft. Die Ausgabe wird dann in eine Schrittfunktion Iterator eingespeist, die gleichzeitig die Lambda-Funktion Calc Metrics für jeden Auftrag aufruft. Diese Lambda-Funktion vergleicht Benutzertransaktionsübereinstimmungen aus einer DocumentDB-Sammlung mit Transaktionsübereinstimmungen, die von unserem in S3 gespeicherten Algorithmus erzeugt wurden, und schreibt die Ergebnisse in unsere MongoDB-Sammlung "Metrics".
Dies ist das von AWS erstellte Workflow-Diagramm:
Dies ist der Code für die Lambda-Anweisung Query Jobs:
def lambda_handler(event, context):
query = {}
query['runDate'] = dict()
query['runDate']['$gte'] = event['date_begin']
query['runDate']['$lte'] = event['date_end']
client = MongoClient(connection_string)
db = client['Analytics']
return list(db.jobs.find(query))
Das Problem bei diesem Ansatz ist, dass die von der Lambda-Funktion Query Jobs zurückgegebenen Ergebnisse potenziell Tausende von Dokumenten umfassen können. AWS begrenzt derzeit die Ausgabegröße einer Step Function-Aufgabe auf 256 KB. Ohne besondere Maßnahmen kann diese Grenze leicht überschritten werden und die Ausführung der Schrittfunktion schlägt fehl:

Ein skalierbarer Ansatz
Die Lösung, die wir gefunden haben, war folgende:
- Begrenzen Sie die Ergebnisse, die aus dem Lambda "Query Jobs" kommen,
- Verarbeiten und speichern Sie die Vergleiche nur auf dieser begrenzten Menge,
- Ermitteln Sie, ob es weitere Ergebnisse gibt,
- In einer Schleife zurück zum Lambda "Query Jobs" wird der Vorgang wiederholt, bis keine Daten mehr vorhanden sind.
Zu diesem Zweck begrenzen wir die Anzahl der von der Lambda-Anweisung Query Jobs zurückgegebenen Dokumente für einen bestimmten Aufruf, indem wir ein Paginierungsschema einführen. Anstatt alle Dokumente auszuwählen, setzen wir ein Abfragelimit und eine spezielle batch_id, um die aktuell abzurufende Seite anzugeben. Wenn mehr Seiten vorhanden sind, gibt das Lambda die batch_id zurück, die die nächste Seite von Dokumenten identifiziert, die bei einem erneuten Aufruf des Lambdas verwendet werden soll. Die batch_id ist vergleichbar mit dem LastEvaluatedKey, der in DynamoDB für die Paginierung verwendet wird. Wir verwenden das interne MongoDB-Feld _id aus der Sammlung "Jobs" in sortierter Reihenfolge als batch_id.
Wir starten den Workflow nun zusätzlich zum Datumsbereich mit einer Losgröße:
{
"date_begin": "2020-08-18T00:00:00",
"date_end": "2020-08-20T23:59:59",
"batch_size": 20
}
In diesem Beispiel wird die Losgröße auf 20 begrenzt.
Der neue Code unten zeigt das Query Jobs Lambda mit zusätzlichen Paging-Funktionen. Wir stellen auch sicher, dass runDate in unserer "Jobs"-Sammlung ordnungsgemäß indiziert ist.
def lambda_handler(event, context):
query = {}
batch_id = event['batch_id']
query['runDate'] = dict()
query['runDate']['$gte'] = event['date_begin']
query['runDate']['$lte'] = event['date_end']
if batch_id:
query['_id'] = dict()
query['_id']['$gt'] = ObjectId(batch_id)
client = MongoClient(connection_string)
db = client['Analytics']
jobs = list(db.jobs.find(query).sort('_id', 1).limit(event['batch_size']))
event['batch_id'] = None
# if there are more results, set the batch_id for the next iteration in the sfn
if len(jobs) >= event['batch_size']:
event['batch_id'] = jobs[-1]['_id']
return dict(
jobs = jobs,
queryParams = event
)
Zusätzlich zu den angeforderten Dokumenten gibt das Lambda auch die Abfrageparameter zurück, die in der nächsten Iteration verwendet werden sollen. Dazu gehört die batch_id für den nächsten Datenstapel. Die Auswahl "Check For More Data" stellt fest, dass eine batch_id existiert und beginnt eine weitere Iteration. Siehe den unten stehenden Ausschnitt aus dem Arbeitsablauf. Bei der nächsten Iteration wird die batch_id mit der letzten _id aus den vorherigen Ergebnissen ausgefüllt und der nächste Stapel von 20 erfasst. Die Abfragekriterien in der Lambda-Anweisung Query Jobs verwenden eine strenge Größer-als-Klausel ($gt) für _id, wenn batch_id existiert. Auf diese Weise ist gewährleistet, dass die Abfrage dort fortgesetzt wird, wo sie beim letzten Mal aufgehört hat.
Sobald die Anzahl der von der Abfrage zurückgegebenen Dokumente geringer ist als die Stapelgröße, wird keine Batch_id gesetzt. Der Auswahlstatus "Check For More Data" erkennt dies und beendet den Workflow.

"Check For More Data": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.data.Payload.queryParams.batch_id",
"IsNull": false,
"Next": "Next Batch"
},
{
"Variable": "$.data.Payload.queryParams.batch_id",
"IsNull": true,
"Next": "Success"
}
],
"Default": "Success"
},
"Next Batch": {
"Type": "Pass",
"Parameters": {
"queryParams.$": "$.data.Payload.queryParams"
},
"Next": "Query Jobs"
}
Da haben Sie es! Jetzt können wir einen Haufen abgefragter Daten durch einen Arbeitsablauf weiterleiten, ohne dass das Ding explodiert!
Was wir gelernt haben
Wie immer hängt die Wahl des ETL-Tools (oder jedes anderen AWS-Tools) vom jeweiligen Anwendungsfall ab. In unserem Fall haben wir gelernt, dass wir einen vorhandenen Step Function-Workflow anpassen können, um eine moderate Menge an Daten zu verarbeiten, ohne dass die Migration zu einem vollwertigen serverlosen ETL-Tool wie AWS Glue zu viel Arbeit macht. In unserem Fall wussten wir, dass wir immer mit Daten in der Größenordnung von Tausenden von Dokumenten zu tun haben würden. Ein Anwendungsfall mit Millionen von Dokumenten würde hingegen einen anderen Ansatz erfordern.
Eine weitere Einschränkung, auf die wir hier nicht eingegangen sind, ist die Begrenzung der Größe der Ausführungshistorie von Schrittfunktionen auf 25.000. Ein Neustart des Workflows als neue Ausführung löst diese Einschränkung.

Mark Panahi
Mark ist ein leitender Software-Ingenieur bei FloQast. Mark liebt Schokocroissants.
Zurück zu Blog